Vicidial Go-Autodial 3.3 Complete Step by Step
Download Gautodial 3.3 ISO and Install File


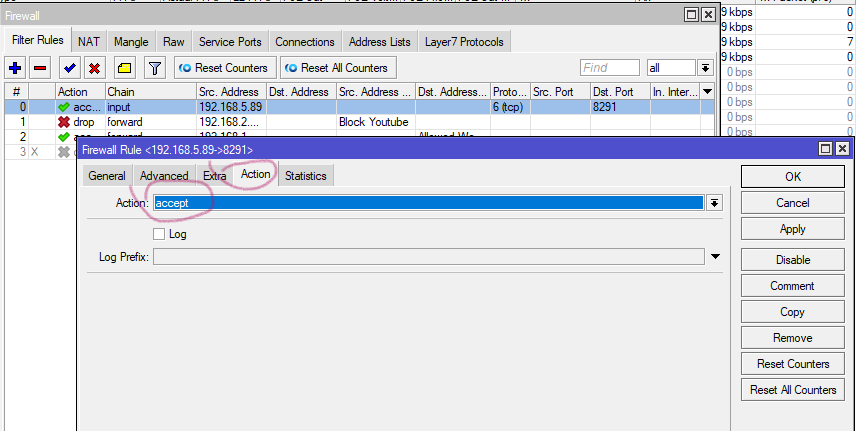
Type Setup command on putty and configure IP's for server


When you are done installation you need to run command to update server IP in Database.
You can login with password that you setup during installation process.
root
vicidial

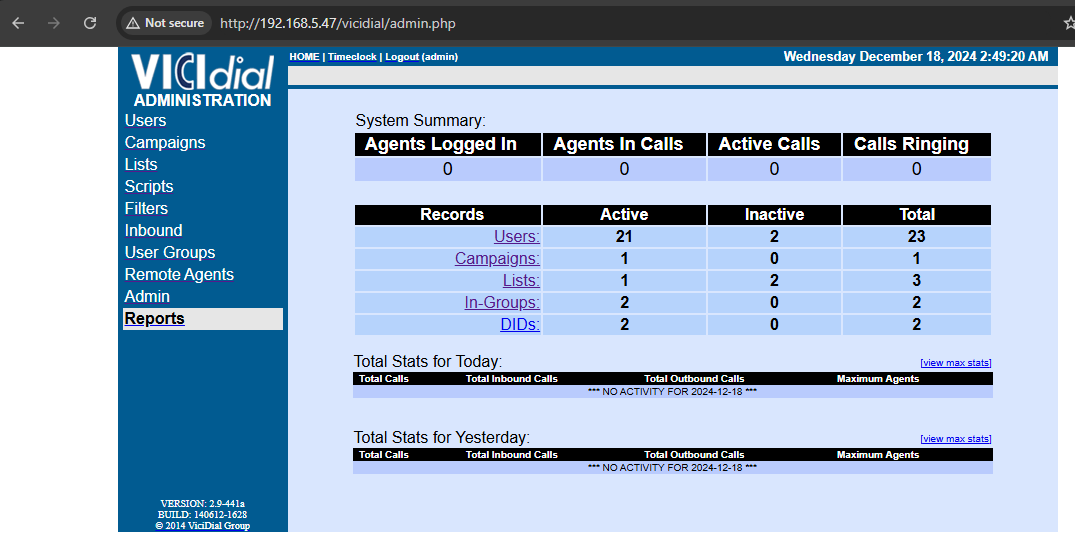
http://192.168.5.47/vicidial/admin.php
admin
vicidialnow
You can access phpmyadmin you need to allow from.
vi /etc/httpd/conf.d/phpmyadmin.conf - Then enter your IP to access it.
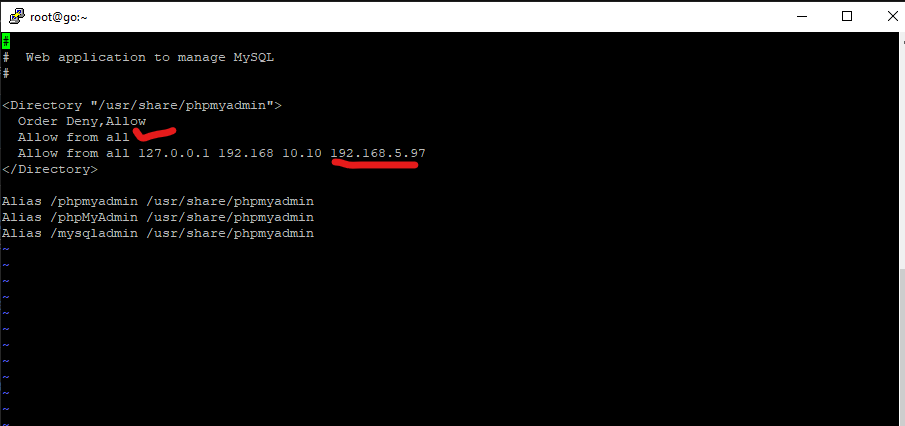
PHP My Admin wested time due to link
http://192.168.5.47/phpMyAdmin/index.php
root
vicidialnow

Linux Cli you can acces database
mysql -p
password vicidialnow
USE asterisk; --------- select database
below command use to change vicidial user password login and phone
update vicidial_users set pass='password123',phone_pass='password123' where user_level=1;
update phones set conf_secret='password123',pass='password123' where 1;
Webmin conf file under vi /etc/webmin/miniserv.conf
Change ssl= from 1 to 0 for http

http://192.168.5.47:10000/
root
vicidial

limesurvey
http://192.168.5.47/limesurvey/admin/admin.php
admin
kamote1234